
MetaGPT X Technical Report
Intruduction
Recently, multi-agent systems powered by Large Language Models (LLMs) have gained popularity for tasks ranging from research to software development. Our goal is to build autonomous agents that significantly accelerate the workflow in software development, enhancing capabilities in natural language programming.
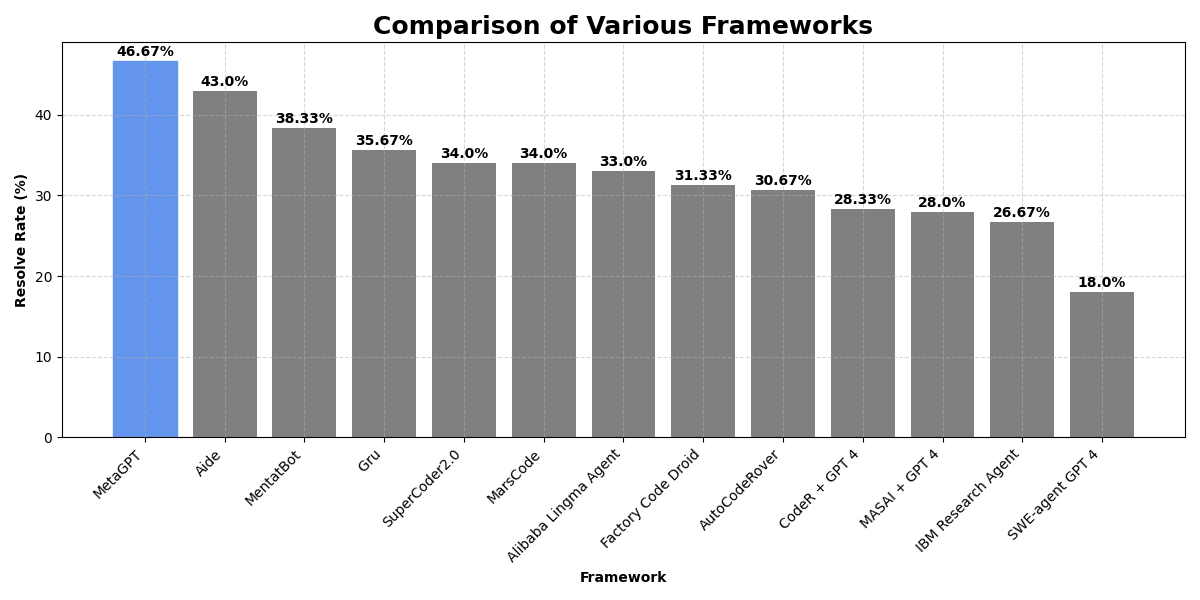
Leveraging multi-agent architecture, we have achieved a 46.67% resolved rate on SWE-Bench Lite, surpassing state-of-the-art frameworks. Built on our open-source framework MetaGPT and driven by GPT-4o and Claude 3.5-Sonnet, our multi-agent team excels in autonomous issue-solving process.
We've enhanced repository-level understanding and equipped agents with sophisticated tools for symbol navigation, code structure visualization, and runtime debugging. This enables them to collaboratively explore codebases, make precise edits with diagnostics, and conduct comprehensive regression tests. This report provides an overview of our framework, offers insights into the multi-agent system and the advanced tools critical for software engineering, and discusses its performance on SWE-Bench Lite.
Framework Overview
Repository-level tasks often require processing large amounts of information and navigating multiple steps to reach a solution. Breaking these tasks into interconnected sub-tasks and addressing them sequentially has proven effective. Issue resolution, a common repository-level challenge, demands identifying buggy code locations, reasoning about solutions, and testing patches.
LLM-based Multi-Agent System
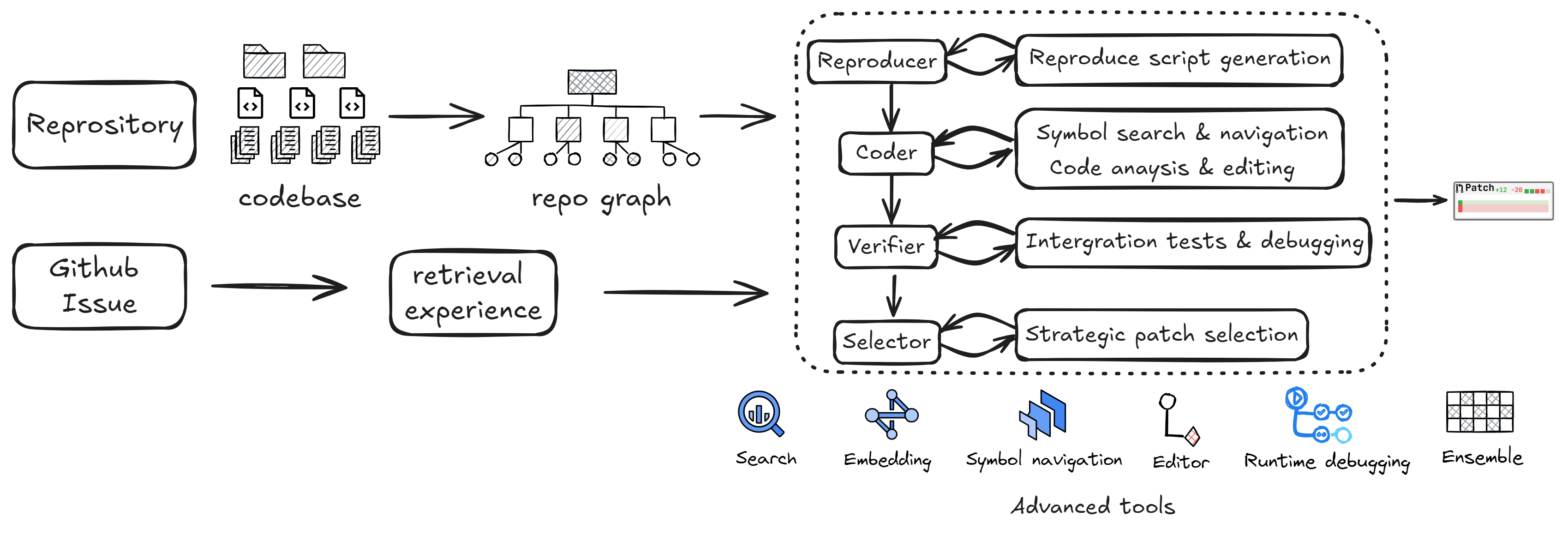
A multi-agent system excels at decoupling roles and utilizing contextual information, enabling more focused and efficient task execution. Instead of relying on a single agent to manage diverse goals, complex reasoning, and long-term memory, we employ a team of specialized agents powered by LLMs. These agents collaboratively tackle the problem through phases of reproduction, analysis and editing, testing and debugging, and patch review and selection, effectively mirroring real-world problem-solving processes.
- Reproducer: The first step in addressing an issue described in natural language or traceback information is to reproduce it by analyzing the issue and using the relevant code. This process is critical for pinpointing the bug, providing contextual information, and observing the runtime behavior to confirm the existence of the problem. During this phase, the reproducer uses search tools to locate relevant code, editing tools to generate reproduction script, runs the script, and then analyzes the observation to confirm the successful issue reproduction.
- Coder: Based on the upstream reproduction results, the coder performs more granular code searches, including symbol-level identification and navigation, while exploring definitions, signatures, docstrings, and call graphs. The coder can click on symbol to quickly access relevant code blocks. At the file level, the coder can obtain the hierarchy structure of the opened script, retrieving complete symbol information within a limited observation window to improve navigation efficiency. During real-time editing, the coder utilizes diagnostics, auto-checks formatting, and includes full line numbers at the code block level to reduce indentation and formatting errors. Additionally, the coder reflects on multiple failed edits by revisiting the context of the error-prone sections or generating in-line comments to enhance the success rate of code modifications.
- Verifier: After the coder generates a patch, the verifier conducts integration tests on both the new patch and existing tests. Notably, the verifier does not have access to the test patch provided by the task, consistent with setups in other frameworks. The verifier performs searches based on patch analysis, extracting symbols from the patch, directly navigating to relevant code blocks, and locating associated test files. It then modifies the code as needed and reflects on runtime debugging. The verifier runs existing regressions tests, reproduces script, or generates new test code to further confirm whether the patch successfully resolves the current issue. If regression tests fail, the execution feedback is propagated back to the verifier to reflect on the feedback and patch.
- Selector: During the issue-solving process, the selector prompts the coder and verifier to generate multiple patches using different LLMs when the model patch is empty or there is no submission in the trajectory. The selector then applies a selection process based on the given patches and problem statement, shuffling the patches multiple times and using a majority voting mechanism to determine the best solution.
Repo Understanding and Advanced Tools
- Repo parser: We enhance repository understanding by constructing a repo-graph using tree-sitter to index codebases, capturing symbols, relationships, and structural metadata like symbol names, signatures, and call graphs. Our tool supports multi-granularity searches (e.g., variables, functions, classes) and returns detailed metadata, facilitating code structure-aware context retrieval and navigation based on issue descriptions as well as surrounding context.
- Search tools: Unlike other file or keyword based search tools, we improve information density within limited windows by offering code block previews with line numbers upon match, allowing agents to gather extensive code context. We simulate an IDE-like environment for actively navigated files, providing hierarchical structure information (classes, functions, methods) with line numbers and indentation. Enhanced click-to-navigate functionality for symbols allows agents to directly expand and view details. This improves efficiency in symbol information collection and reduces redundant navigation, particularly in large files and complex dependency hierarchies.
- Code semantic search: To enhance search quality in codebases rich with symbols, we iteratively chunk repositories at the method level and embed each code block using an embedding model. This enables our agents to locate buggy code by retrieving relevant code spans and associated file information from a code semantic perspective, complementing the limitations of the previous two search methods.
- Enhanced editor: We update the file editor to include code block contexts with line numbers, significantly reducing syntax errors and indentation issues that frequently occur during code generation.
- Runtime debugging: Utilizing LLMs, we provide tools line-by-line code explanations based on runtime tracebacks (e.g., assertion errors) or regression test results. We enable runtime debugging by displaying variable values and generating in-line comments for executed code, significantly improving code generation quality through an iterative debugging process with LLMs.
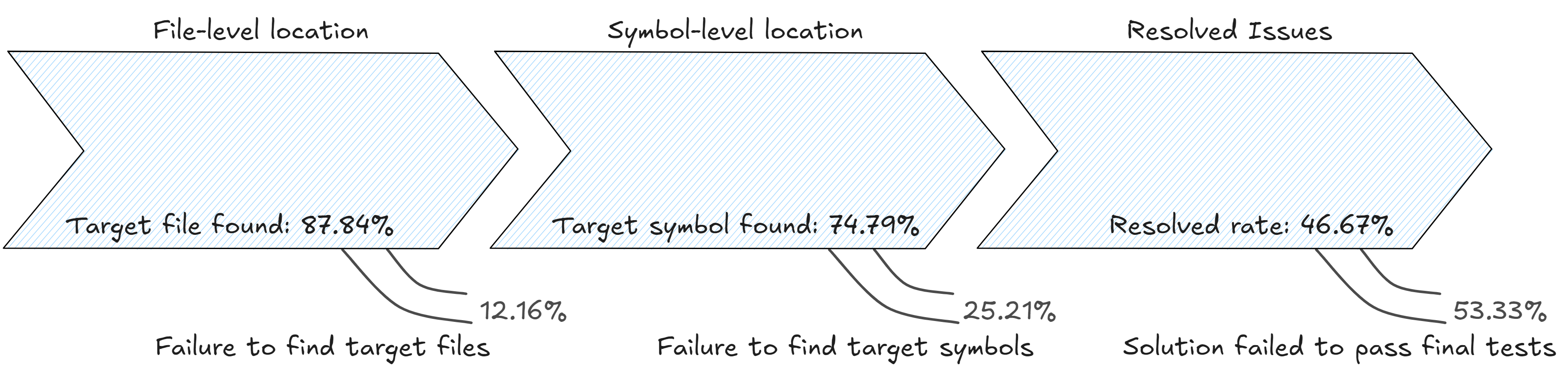
SWE-Bench Lite
Background
SWE-Bench is designed to provide a diverse set of codebase problems that were verifiable using in-repo unit tests. The full SWE-bench test split comprises 2,294 issue-commit pairs across 12 python repositories. SWE-Bench Lite is a canonical subset of SWE-bench, comprising 300 instances from SWE-bench that have been sampled to be more self-contained, with a focus on evaluating functional bug fixes. SWE-bench Lite covers 11 of the original 12 repositories in SWE-bench, with a similar diversity and distribution of repositories as the original. The AI system is given the problem statement extracted from the GitHub issue and the repository itself and is expected to generate a git patch to resolve the issue. The patch is then evaluated against unit tests that verify if the patch resolves the issue.
Evaluation
Our system is set up to autonomously complete the issue solving process on each instance. We employ four agents and abandoned access to the internet, using the problem statement provided in the dataset to solve. In the early stages of our experiments, the official evaluation tools were unstable and prone to errors. Therefore, we adopted the open-sourced SWE-bench-docker tools, which provided a dockerized setup and simplified the evaluation process by eliminating the need for manual environment configuration. Additionally, we are now conducting evaluations using the stable containerized evaluation harness provided by the benchmark team to further enhance reliability and reproducibility.
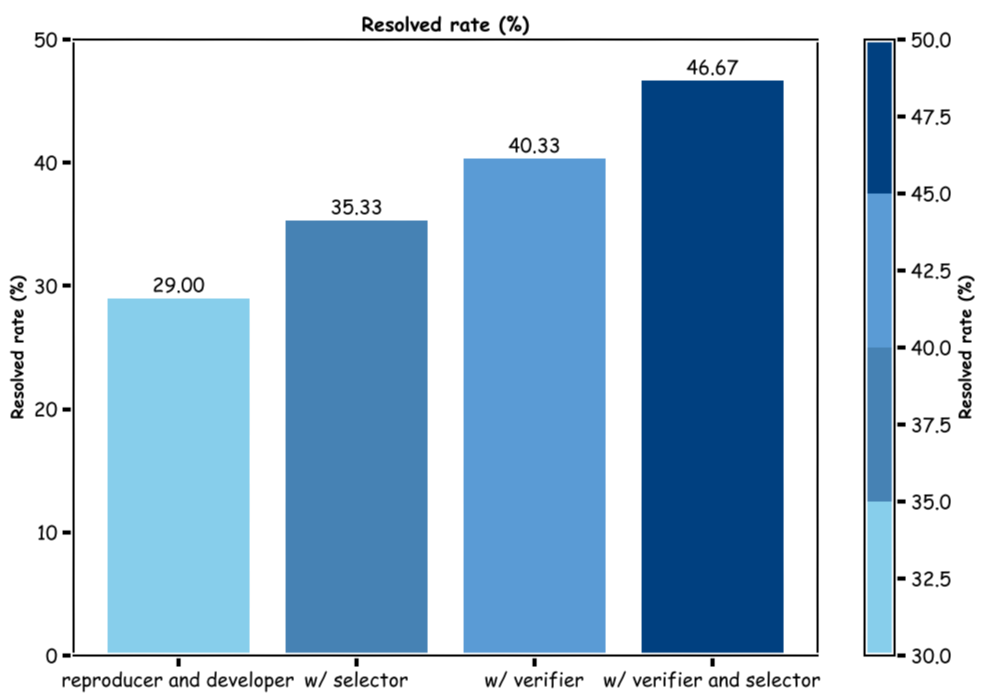
Performance
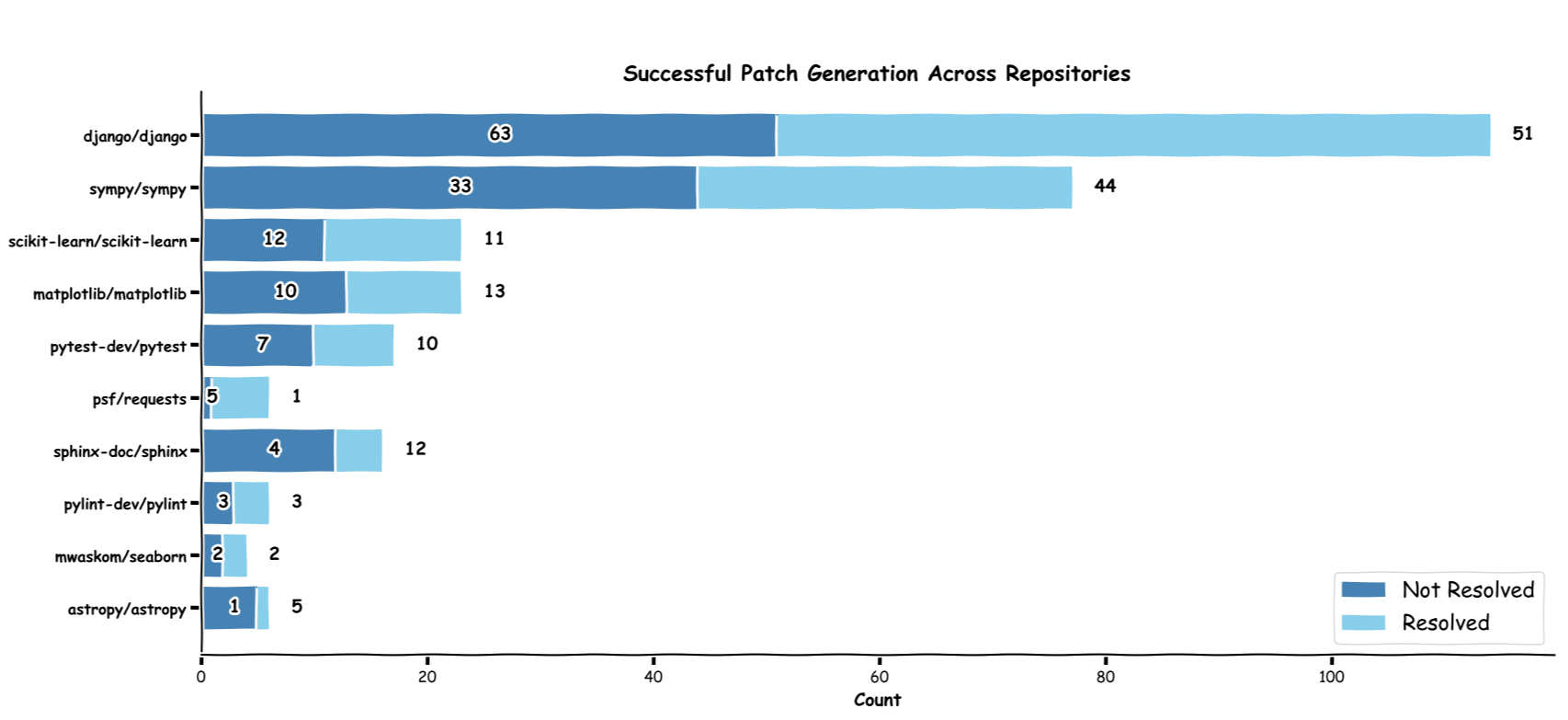
Conclusion and future work
We have developed multi-agent systems to address complex issue-solving tasks, including issue reproduction, efficient code generation and verification, and robust patch selection. These agents utilize advanced repo-level code understanding, search, editing, and debugging capabilities, demonstrating significant potential across various software engineering subtasks.
- Multi-agent collaboration: Agents collaborate to declare tasks, tools, and symbols, solving them independently. This approach enhances issue resolution success and enables the handling of more complex problems.
- SOP (Standard Operating Procedure) generation: Agents autonomously gather problem-solving data to construct and refine SOPs. Agents automatically design and construct problem-solving workflows for different tasks by building a graph based on task scale, problem similarity, and prior problem-solving experience. They then use the graph solver to generate and iterate on SOPs, ensuring that each step is optimized for efficiency and effectiveness.
- Fine-tuning based on trajectory and feedback: Throughout the issue-solving process, agents generate comprehensive trajectories based on tool usage decisions informed by environmental feedback, covering symbol retrieval, generation, and testing. These trajectories can be harnessed to refine LLM capabilities in complex software engineering scenarios, suggesting that further fine-tuning could enhance the agents' ability to autonomously plan and analyze challenges within software development contexts.
Acknowledgments
Thanks to the SWE-bench and SWE-Agent Teams, and Albert Örwall (SWE-bench-docker) as well as OpenAI and Anthropic.